嵌入置信度¶
在现实生活中,通常需要知道模型对预测有多大信心。这有助于判断是否需要对手动调整或验证结果。
对于传统分类,很容易通过分数来理解模型对结果的信心。如果不同类别的概率值接近,则模型信心不足。相反,如果最可能类别显著不同,则模型信心十足。
乍一看,我们无法将此技术应用于相似度学习。即使预测的对象相似度分数很小,也可能仅仅意味着参考集中没有合适的比较对象。相反,模型可能会将垃圾对象分到高分数组。
幸运的是,嵌入生成器有一个小的修改,允许您以与传统分类器使用 Softmax 激活函数相同的方式定义置信度。
该修改在于将嵌入构建为特征组的组合。每个特征组在嵌入中表示为一个独热编码的子向量。如果模型能够自信地预测特征值,则相应的子向量在其某些元素中将具有较高的绝对值。为了更直观的理解,我们建议不要将嵌入视为空间中的点,而是视为一组二元特征。
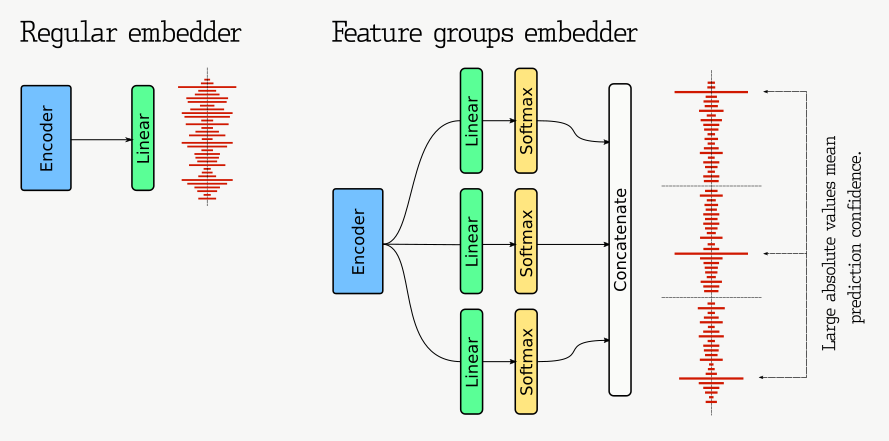
为了实现这一修改并形成适当的特征组,我们需要将常规线性输出层更改为多个 softmax 层的级联。每个 softmax 组件将代表一个独立特征,并迫使神经网络学习它们。
让我们以 4 个 softmax 组件为例,每个组件包含 128 个元素。每个这样的组件都可以大致想象为从 0 到 127 的独热编码数字。因此,最终向量将代表 128⁴ 种可能组合中的一种。如果训练好的模型足够好,您甚至可以尝试单独解释单个特征的值。
Quaterion 提供了一个现成的头部层,可以实现特征组嵌入。
class Model(TrainableModel):
...
def configure_head(self, input_embedding_size: int) -> EncoderHead:
return SoftmaxEmbeddingsHead(
output_groups=4,
output_size_per_group=128,
input_embedding_size=input_embedding_size
)
