使用相似性学习搜索相似汽车¶
本教程的重点是使用 Quaterion 逐步解决相似性学习问题。具体来说,我们将训练一个相似性模型来搜索相似的汽车。这还将帮助我们更好地理解 Quaterion 中的一些基本构建块如何在实际项目中协同工作。让我们开始逐步讲解代码中的一些重要部分。
如果您正在寻找完整的源代码,可以在 Quaterion 仓库的 示例 目录中找到。
数据集¶
在本教程中,我们将使用 Stanford Cars 数据集。它包含来自 196 个类别的 16185 张汽车图片,并以 लगभग 50-50% 的比例分为训练和测试子集。

汽车图片示例¶
然而,为了让事情变得更有趣,我们将首先合并训练和测试子集,然后再将其分成两部分,以便将 196 个类别中的一半放入训练集,另一半放入测试集。这将使我们能够使用模型在训练阶段从未见过的新类别样本进行测试,这是监督分类无法实现但相似性学习可以实现的功能。
以下代码摘自 data.py
get_datasets()函数执行上述分割任务。get_dataloaders()函数从训练和测试数据集中创建GroupSimilarityDataLoader实例。数据集是常规的 PyTorch 数据集,发出
SimilarityGroupSample实例。
注:目前,Quaterion 有两种数据类型来表示数据集中的样本。要了解更多关于 SimilarityPairSample 的信息,请查阅自然语言处理教程。
import numpy as np
import os
import tqdm
from torch.utils.data import Dataset, Subset
from torchvision import datasets, transforms
from typing import Callable
from pytorch_lightning import seed_everything
from quaterion.dataset import (
GroupSimilarityDataLoader,
SimilarityGroupSample,
)
# set seed to deterministically sample train and test categories later on
seed_everything(seed=42)
# dataset will be downloaded to this directory under local directory
dataset_path = os.path.join(".", "torchvision", "datasets")
class CarsDataset(Dataset):
def __init__(self, dataset: Dataset, transform: Callable):
self._dataset = dataset
self._transform = transform
def __len__(self) -> int:
return len(self._dataset)
def __getitem__(self, index) -> SimilarityGroupSample:
image, label = self._dataset[index]
image = self._transform(image)
return SimilarityGroupSample(obj=image, group=label)
def get_datasets(input_size: int):
# Use Mean and std values for the ImageNet dataset as the base model was pretrained on it.
# taken from https://www.geeksforgeeks.org/how-to-normalize-images-in-pytorch/
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
# create train and test transforms
transform = transforms.Compose(
[
transforms.Resize((input_size, input_size)),
transforms.ToTensor(),
transforms.Normalize(mean, std),
]
)
# we need to merge train and test splits into a full dataset first,
# and then we will split it to two subsets again with each one composed of distinct labels.
full_dataset = datasets.StanfordCars(
root=dataset_path, split="train", download=True
) + datasets.StanfordCars(root=dataset_path, split="test", download=True)
# full_dataset contains examples from 196 categories labeled with an integer from 0 to 195
# randomly sample half of it to be used for training
train_categories = np.random.choice(a=196, size=196 // 2, replace=False)
# get a list of labels for all samples in the dataset
labels_list = np.array([label for _, label in tqdm.tqdm(full_dataset)])
# get a mask for indices where label is included in train_categories
labels_mask = np.isin(labels_list, train_categories)
# get a list of indices to be used as train samples
train_indices = np.argwhere(labels_mask).squeeze()
# others will be used as test samples
test_indices = np.argwhere(np.logical_not(labels_mask)).squeeze()
# now that we have distinct indices for train and test sets, we can use `Subset` to create new datasets
# from `full_dataset`, which contain only the samples at given indices.
# finally, we apply transformations created above.
train_dataset = CarsDataset(
Subset(full_dataset, train_indices), transform=transform
)
test_dataset = CarsDataset(
Subset(full_dataset, test_indices), transform=transform
)
return train_dataset, test_dataset
def get_dataloaders(
batch_size: int,
input_size: int,
shuffle: bool = False,
):
train_dataset, test_dataset = get_datasets(input_size)
train_dataloader = GroupSimilarityDataLoader(
train_dataset, batch_size=batch_size, shuffle=shuffle
)
test_dataloader = GroupSimilarityDataLoader(
test_dataset, batch_size=batch_size, shuffle=False
)
return train_dataloader, test_dataloader
可训练模型¶
现在是回顾 TrainableModel 的时候了,它是您想要配置进行训练的模型的基类。它提供了几个以 configure_ 开头的钩子方法,用于设置训练阶段的各个方面,就像其自身的基类 pl.LightningModule 一样。它是使用 Quaterion 进行微调的核心,因此我们将分解 models.py 中的这段关键代码并分别回顾每个方法。让我们从导入开始
import torch
import torchvision
from quaterion_models.encoders import Encoder
from quaterion_models.heads import EncoderHead, SkipConnectionHead
from torch import nn
from typing import Dict, Union, Optional, List
from quaterion import TrainableModel
from quaterion.eval.attached_metric import AttachedMetric
from quaterion.eval.group import RetrievalRPrecision
from quaterion.loss import SimilarityLoss, TripletLoss
from quaterion.train.cache import CacheConfig, CacheType
from .encoders import CarsEncoder
在以下代码片段中,我们对 TrainableModel 进行子类化。您可以使用 __init__() 来存储一些属性,以便在后续的各种 configure_* 方法中使用。然而,更有趣的部分在于 configure_encoders() 方法。我们需要从该方法返回一个 Encoder 实例(或者一个以 Encoder 实例作为值的字典)。在我们的示例中,它是一个 CarsEncoders 实例,我们很快就会回顾它。现在请注意它是如何使用一个预训练的 ResNet152 模型创建的,该模型的分类层已被恒等函数替换。
class Model(TrainableModel):
def __init__(self, lr: float, mining: str):
self._lr = lr
self._mining = mining
super().__init__()
def configure_encoders(self) -> Union[Encoder, Dict[str, Encoder]]:
pre_trained_encoder = torchvision.models.resnet152(pretrained=True)
pre_trained_encoder.fc = nn.Identity()
return CarsEncoder(pre_trained_encoder)
在 Quaterion 中,一个 SimilarityModel 由一个或多个 Encoder 和一个 EncoderHead 组成。quaterion_models 有 几种 EncoderHead 实现,具有统一的 API,例如可配置的 dropout 值。您可以使用其中之一或创建自己的 EncoderHead 子类。无论哪种情况,您都需要从 configure_head 返回其一个实例。在此示例中,我们将使用 SkipConnectionHead,它轻量级且更抗过拟合。
def configure_head(self, input_embedding_size) -> EncoderHead:
return SkipConnectionHead(input_embedding_size, dropout=0.1)
Quaterion 实现了一些流行的相似性学习损失函数,所有这些函数都继承自 GroupLoss 或 PairwiseLoss。在此示例中,我们将使用 TripletLoss,它是 GroupLoss 的子类。通常,GroupLoss 的子类用于样本被分配到某个组(或标签)的数据集。在我们的示例中,标签是汽车的品牌。这些数据集应发出 SimilarityGroupSample。其他替代方案是 PairwiseLoss 的实现,它使用 SimilarityPairSample - 一对独立指定相似性的对象。要查看后者的示例,您可能需要查阅自然语言处理教程。
def configure_loss(self) -> SimilarityLoss:
return TripletLoss(mining=self._mining, margin=0.5)
configure_optimizers() 可能对 PyTorch Lightning 用户来说很熟悉,但该方法内部使用了一个新的 self.model。它是 SimilarityModel 的一个实例,由 Quaterion 根据 configure_encoders() 和 configure_head() 的返回值自动创建。
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.model.parameters(), self._lr)
return optimizer
Quaterion 中的缓存用于避免在每个 epoch 中重复计算冻结的预训练 Encoder 的输出。配置后,输出将计算一次并缓存在首选设备中供以后直接使用。这既提供了可观的加速,又减少了内存占用。然而,它功能相当强大且有多个可调参数。为了充分发挥其潜力,建议您查阅缓存教程。为了使本文独立完整,您需要从 configure_caches() 返回一个 CacheConfig 实例,以指定与缓存相关的偏好设置,例如
CacheType,即是将缓存存储在 CPU 还是 GPU 上,
save_dir,即存储缓存以供后续运行的地方,batch_size,即仅在创建缓存时使用的批处理大小 - 实际训练期间使用的批处理大小可能不同。
def configure_caches(self) -> Optional[CacheConfig]:
return CacheConfig(
cache_type=CacheType.AUTO, save_dir="./cache_dir", batch_size=32
)
我们刚刚配置了 TrainableModel 的训练相关设置。然而,评估是机器学习实验不可或缺的一部分,您可以通过从 configure_metrics() 返回一个或多个 AttachedMetric 实例来配置评估指标。Quaterion 内置了几种组和成对评估指标。
def configure_metrics(self) -> Union[AttachedMetric, List[AttachedMetric]]:
return AttachedMetric(
"rrp",
metric=RetrievalRPrecision(),
prog_bar=True,
on_epoch=True,
on_step=False,
)
编码器¶
如前所述,一个 SimilarityModel 由一个或多个 Encoder 和一个 EncoderHead 组成。即使我们冻结预训练的 Encoder 实例,EncoderHead 仍然是可训练的,并且有足够的参数来适应当前的新任务。建议您尽可能将 trainable 属性设置为 False,因为它允许您从上述缓存机制中获益。另一个重要的属性是 embedding_size,它将作为 input_embedding_size 传递给 TrainableModel.configure_head(),以便您正确初始化头部层。让我们看看在以下代码中如何实现一个 Encoder,该代码摘自 encoders.py
import os
import torch
import torch.nn as nn
from quaterion_models.encoders import Encoder
class CarsEncoder(Encoder):
def __init__(self, encoder_model: nn.Module):
super().__init__()
self._encoder = encoder_model
self._embedding_size = 2048 # last dimension from the ResNet model
@property
def trainable(self) -> bool:
return False
@property
def embedding_size(self) -> int:
return self._embedding_size
一个 Encoder 是一个常规的 torch.nn.Module 子类,我们需要在 forward 方法中实现前向传播逻辑。根据您创建子模块的方式,此方法可能会更复杂;但是,在此示例中,我们只需将输入通过预训练的 ResNet152 主干网络传递。
def forward(self, images):
embeddings = self._encoder.forward(images)
return embeddings
机器学习开发的重要一步是正确保存和加载模型。Quaterion 允许您使用 TrainableModel.save_servable() 保存您的 SimilarityModel,并使用 SimilarityModel.load() 恢复它。为了能够使用这两个方法,您需要在 Encoder 中实现 save() 和 load() 方法。此外,重要的是将您的 Encoder 子类定义在 __main__ 命名空间之外,即与主入口点分开的文件中。否则可能无法正确恢复。
def save(self, output_path: str):
os.makedirs(output_path, exist_ok=True)
torch.save(self._encoder, os.path.join(output_path, "encoder.pth"))
@classmethod
def load(cls, input_path):
encoder_model = torch.load(os.path.join(input_path, "encoder.pth"))
return CarsEncoder(encoder_model)
训练¶
实现了所有基本对象后,就可以轻松地将它们整合在一起,并使用 Quaterion.fit() 方法运行训练循环。它需要
一个
TrainableModel,一个 pl.Trainer,
用于训练数据的 SimilarityDataLoader,
以及可选的,用于评估数据的另一个
SimilarityDataLoader。
我们需要导入一些对象来准备所有这些内容
import os
import pytorch_lightning as pl
import torch
from pytorch_lightning.callbacks import EarlyStopping, ModelSummary
from quaterion import Quaterion
from .data import get_dataloaders
from .models import Model
以下代码片段中的 train() 函数需要一些超参数值作为参数。它们可以在 config.py 中定义或从命令行传递。但是,为了简洁起见,该部分代码已省略。取而代之的是,让我们重点关注如何初始化所有构建块并将它们传递给负责运行整个循环的 Quaterion.fit()。当训练循环完成后,您只需调用 TrainableModel.save_servable() 即可保存 SimilarityModel 实例的当前状态。
def train(
lr: float,
mining: str,
batch_size: int,
epochs: int,
input_size: int,
shuffle: bool,
save_dir: str,
):
model = Model(
lr=lr,
mining=mining,
)
train_dataloader, val_dataloader = get_dataloaders(
batch_size=batch_size, input_size=input_size, shuffle=shuffle
)
early_stopping = EarlyStopping(
monitor="validation_loss",
patience=50,
)
trainer = pl.Trainer(
gpus=1 if torch.cuda.is_available() else 0,
max_epochs=epochs,
callbacks=[early_stopping, ModelSummary(max_depth=3)],
enable_checkpointing=False,
log_every_n_steps=1,
)
Quaterion.fit(
trainable_model=model,
trainer=trainer,
train_dataloader=train_dataloader,
val_dataloader=val_dataloader,
)
model.save_servable(save_dir)
评估¶

原始模型与微调模型在检索上的比较¶
让我们看看通过这些简单步骤我们取得了什么成就。evaluate.py 有两个函数,用于评估基线模型和微调后的相似性模型。为了简洁起见,我们只回顾后者。除了轻松恢复 SimilarityModel 之外,这段代码片段还展示了如何使用 Evaluator 并通过给定的评估指标来评估 SimilarityModel 在给定数据集上的性能。对整个数据集进行全面评估通常呈指数级增长,因此您可能希望对采样子集进行部分评估。在这种情况下,您可以使用采样器来限制评估。与用于训练的 Quaterion.fit() 类似,Quaterion.evaluate() 运行完整的评估循环。它接受以下参数:
使用给定的评估指标和
Sampler创建的Evaluator实例,要评估的
SimilarityModel,以及评估数据集。
def eval_tuned_encoder(dataset, device):
print("Evaluating tuned encoder...")
tuned_cars_model = SimilarityModel.load(
os.path.join(os.path.dirname(__file__), "cars_encoders")
).to(device)
tuned_cars_model.eval()
result = Quaterion.evaluate(
evaluator=Evaluator(
metrics=RetrievalRPrecision(),
sampler=GroupSampler(sample_size=1000, device=device, log_progress=True),
),
model=tuned_cars_model,
dataset=dataset,
)
print(result)
结论¶
在本教程中,我们训练了一个相似性模型,用于搜索训练阶段未见过的新类别中的相似汽车。然后,我们在测试数据集上使用检索 R-Precision 指标对其进行了评估。基础模型得分为 0.1207,而我们的微调模型达到了 0.2540,得分提高了两倍。这些分数可以在下图中看到
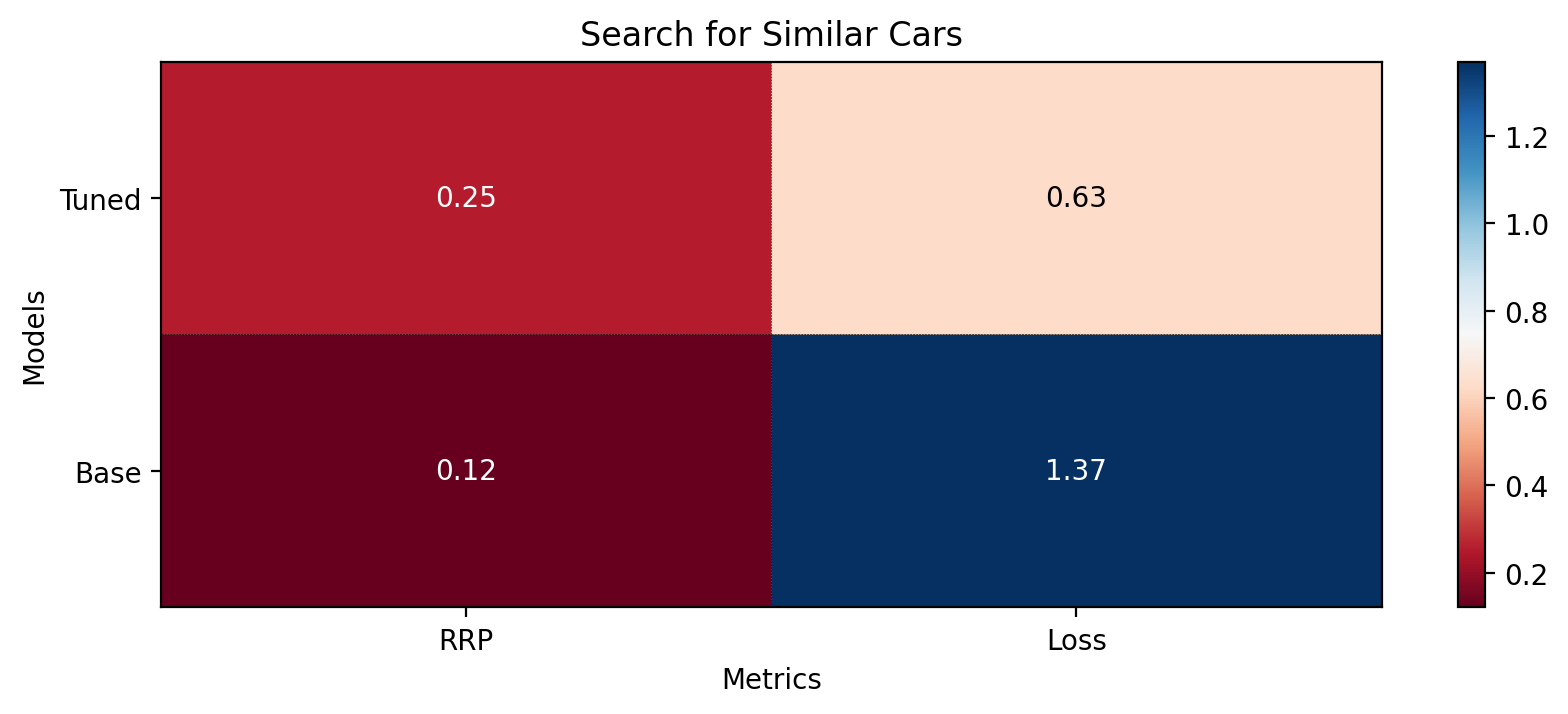
基础模型和微调模型的指标¶
