主要思想¶
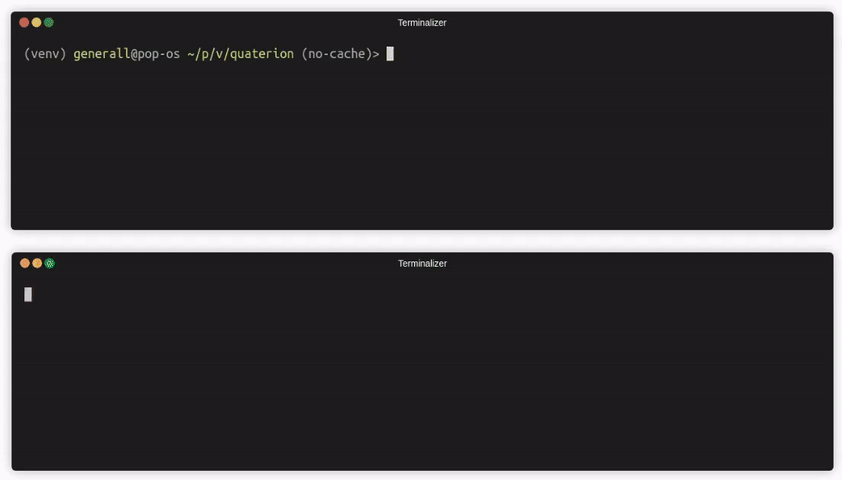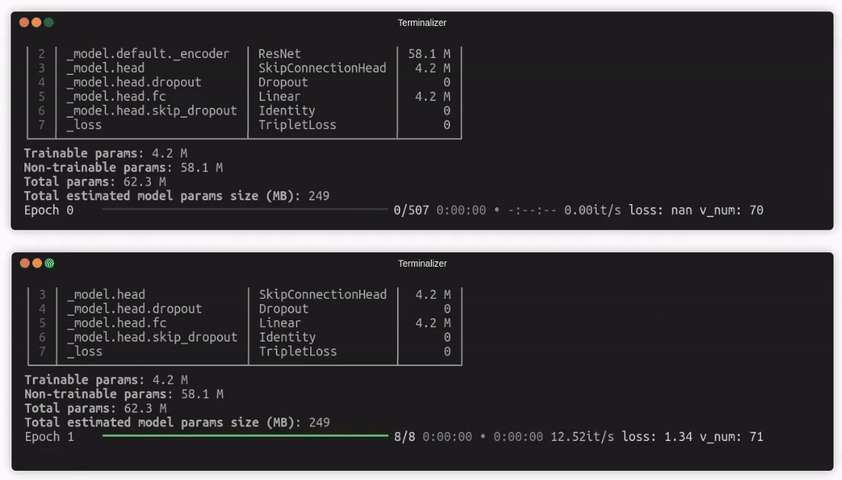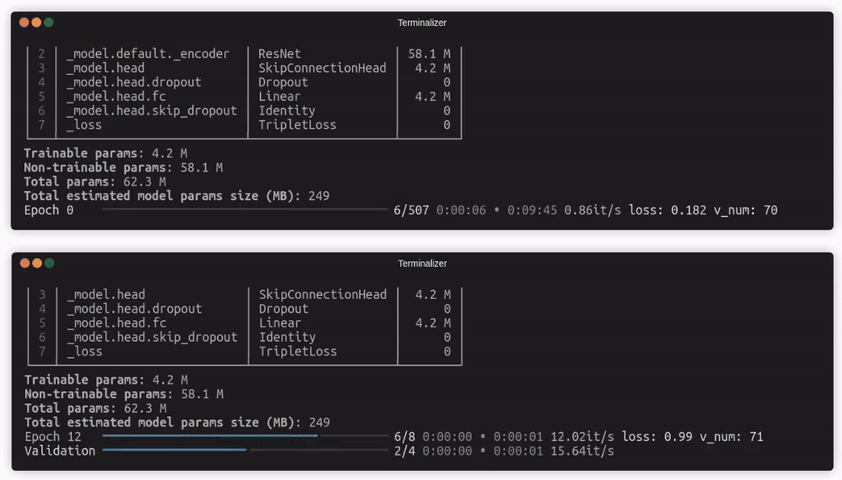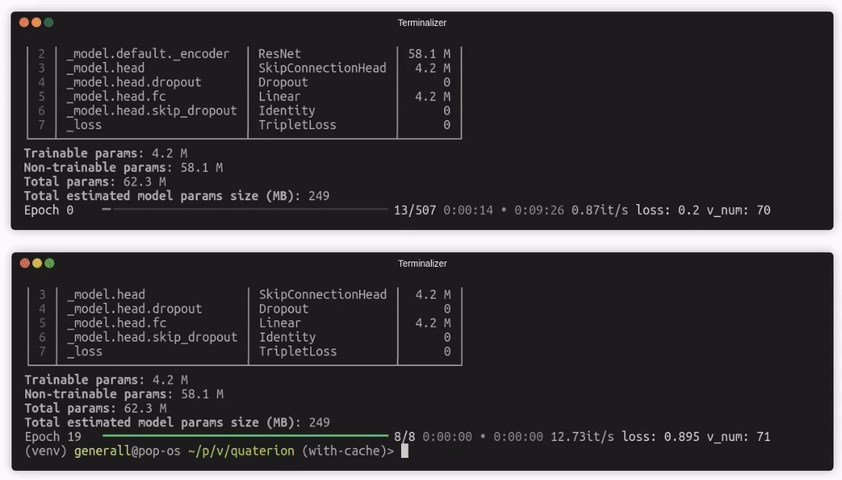
Quaterion 最引人入胜的特性之一是缓存机制。这是一个能让实验极速进行的工具。
在微调过程中,你使用预训练模型并在其顶部连接一个或多个层。这种设置中最消耗资源的部分是通过预训练层进行推理。它们通常有大量的参数。
然而,在许多情况下,你甚至不想更新预训练权重。如果数据不多,最好只调整头部层,以防止过拟合和灾难性遗忘。冻结层不需要计算梯度。因此,可以更快地进行训练。
同时,Quaterion 更进一步。
在 Quaterion 中,预训练模型被用作编码器。如果编码器的权重被冻结,那么它就是确定性的,并且在每个 epoch 对相同的输入发出相同的嵌入。这为显著改进提供了空间——我们可以计算这些嵌入一次,并在训练期间重复使用它们。
这就是缓存的主要思想。
如何使用它?¶
TrainableModel 具有 configure_caches 方法,你需要重写它来使用缓存。
这个方法应该返回一个包含缓存设置的 CacheConfig 实例。
configure_caches 定义¶
def configure_caches(self) -> Optional[CacheConfig]:
return CacheConfig(...)
缓存设置可以根据其目的分为几个部分
管理初始缓存填充的参数
选择嵌入的存储位置
自定义对象如何被缓存
选项概述¶
选项的第一部分包括 batch_size 和 num_workers - 这些参数直接传递给 dataloader,用于填充缓存的过程。
batch_size - 用于缓存编码器推理,不影响训练过程。可能有助于调整内存/速度平衡。
num_workers 确定在填充缓存期间使用的进程数。
调整缓存填充速度¶
cache_type、mapping 和 save_dir。def configure_caches(self) -> Optional[CacheConfig]:
return CacheConfig(
batch_size=16,
num_workers=2
)
前两个选项配置存储缓存嵌入的设备。
cache_type 为所有将被缓存的编码器设置默认存储类型。目前,你可以将嵌入存储在 CPU 或 GPU 上。
mapping 提供了一种为每个编码器单独定义 cache_type 的方式。
最后一个选项 save_dir 设置磁盘上的目录,用于存储嵌入以供后续运行。如果你不指定存储嵌入的目录,每次启动训练时 Quaterion 都会填充缓存。
调整存储¶
def configure_caches(self) -> Optional[CacheConfig]:
return CacheConfig(
cache_type=CacheType.GPU, # GPU as a default storage for frozen encoders embeddings
mapping={"image_encoder": CacheType.CPU} # Store `image_encoder` embeddings on CPU
save_dir='cache'
)
进一步优化¶
尽管通过缓存消除了最耗时的操作,可能仍有一些地方会阻止你的训练循环达到极速 🌀。
数据集通常包含用于训练的特征和标签,在典型设置中,特征仅用于创建嵌入。如果已经有了所有嵌入,原始特征实际上就不再需要了。此外,从磁盘读取特征可能产生显著的 I/O 开销,成为训练期间的瓶颈。
这里一个可能的改进是避免读取数据集,并在填充缓存时也保留标签。如果启用了缓存并满足下一章描述的限制,Quaterion 将自动执行此操作,并显著提高训练速度。
限制¶
使用缓存需要满足几个条件
至少一个编码器应该被冻结。
数据集在每个 epoch 都应该相同。
- 不幸的是,这意味着缓存不支持动态数据增强。
数据集缓存有更严格的规则
所有编码器都必须被冻结。如果至少有一个没有被冻结,我们就无法缓存标签。
不允许使用多进程。
键提取没有被重写。
多进程¶
缓存的标签存储在关联的数据集实例中。因此,这个实例以及随之而来的标签缓存,都绑定到创建它的进程。如果我们使用多进程,那么标签缓存在子进程中填充。在训练期间,我们从父进程中无法访问标签缓存,这使得在这种情况下难以使用多进程。
你可以在缓存配置中使用 num_workers=None 来阻止在填充缓存期间使用多进程。如果你的训练过程受限于 I/O,则首选使用单进程缓存。例如,从磁盘读取图像可能是缓存训练中的瓶颈。但对于 NLP 任务,更多的 CPU 用于预处理可能比 I/O 速度更有影响。
键提取器¶
键提取器是用于获取要存储在缓存中的条目的键的函数。默认情况下,key_extractor 使用数据集中项目的索引作为缓存键。这通常是足够的,但是它有一些你可能想要避免的缺点。
例如,在某些情况下,与数据无关的键可能不可接受或不理想。
你可以提供自定义的 key_extractors,并以自己的方式从特征中提取键,以获得所需的行为。
如果你使用自定义键提取器,则需要在训练期间访问特征以从中获取键。但是从数据集中检索特征正是我们在缓存标签时想要避免的操作。因此,使用自定义键提取器使得标签缓存成为不可能。
提供自定义键提取器¶
def configure_caches(self) -> Optional[CacheConfig]:
def custom_key_extractor(feature):
return feature['filename'] # let's assume we have a dict as a feature
return CacheConfig(
key_extractor=custom_key_extractor # use feature's filename as a key
)
现在我们了解了缓存的所有选项和限制,可以看一个更全面的示例。
综合示例¶
content_encoder 和 attitude_encoder。其中一个将嵌入存储在 GPU 上,另一个存储在 CPU 上。def configure_caches(self) -> Optional[CacheConfig]:
def custom_key_extractor(self, feature):
# let's assume that features is a row and its first 10 symbols uniquely determines it
return features[:10]
return CacheConfig(
mapping={
"content_encoder": CacheType.GPU,
# Store cache in GPU for `content_encoder`
"attitude_encoder": CacheType.CPU
# Store cache in RAM for `attitude_encoder`
},
batch_size=16,
save_dir='cache_dir', # directory on disk to store filled cache
num_workers=2, # Number of processes. Labels can't be cached if `num_workers` != 0
key_extractors=custom_key_extractor # Key extractor for each encoder.
# Equal to
# {
# "content_encoder": custom_key_extractor,
# "attitude_encoder": custom_key_extractor
# }
)
缓存以大小为 16 的批次填充。
缓存填充完成后,它将存储在当前路径下的 cache_dir 中。
缓存填充将在两个进程中执行,每个编码器的嵌入将存储在通过 custom_key_extractor 提取的键下。多进程环境和自定义键提取器不允许我们缓存标签。但对于文本数据来说,避免 I/O 并不是那么重要,因为字符串不像图像那样重,不会产生太多开销。
更多示例可在 configure_caches 文档中找到。
利用缓存的完整训练管道可以在NLP 教程中找到。
