基于相似度学习的问答¶
引言¶
在本教程中,我们将解决一个问答 (Q&A) 问题,以展示如何使用相似度学习和 Quaterion 解决常见的自然语言处理任务。
我们将使用 cloud-faq-dataset。这是从流行的云服务提供商的 F.A.Q. 页面收集的近 8.5k 对问题和答案。

FAQ 部分示例¶
Quaterion 中通常的流程包括以下步骤
下载并准备数据集
创建 Encoder
训练
评估
我们将坚持这个流程,一步一步地实现。
(对于不感兴趣阅读文本的用户 - 这里是包含整个教程代码的 仓库。)
下载并准备数据集¶
数据可以通过以下 bash 命令下载
$ wget https://storage.googleapis.com/demo-cloud-faq/dataset/cloud_faq_dataset.jsonl -O cloud_faq_dataset.jsonl
数据集中呈现的对示例
问题: 由 AWS Graviton2 处理器驱动的 AWS Lambda 函数的定价是多少?
答案: 由 AWS Graviton2 处理器驱动的 AWS Lambda 函数比基于 x86 的 Lambda 函数便宜 20%
数据必须表示为 SimilaritySample 实例。对于问题和答案,我们可以使用 SimilarityPairSample。
class SimilarityPairSample:
obj_a: Any # question
obj_b: Any # answer
score: float = 1.0 # Measure of similarity. Usually converted to bool
# Consider all examples outside this group as negative samples.
# By default, all samples belong to group 0 - therefore other samples could not be used as negative examples.
subgroup: int = 0
我们将使用 torch.utils.data.Dataset 来转换数据并将其馈送到模型。
数据拆分的代码已省略,但可以在 仓库 中找到。
import json
from typing import List, Dict
from torch.utils.data import Dataset
from quaterion.dataset.similarity_samples import SimilarityPairSample
class FAQDataset(Dataset):
def __init__(self, dataset_path):
self.dataset: List[Dict[str, str]] = self.read_dataset(dataset_path)
def __getitem__(self, index) -> SimilarityPairSample:
line = self.dataset[index]
question = line["question"]
# All questions have a unique subgroup
# Meaning that all other answers are considered negative pairs
subgroup = hash(question)
score = 1
return SimilarityPairSample(
obj_a=question, obj_b=line["answer"], score=score, subgroup=subgroup
)
def __len__(self):
return len(self.dataset)
@staticmethod
def read_dataset(dataset_path) -> List[Dict[str, str]]:
"""Read jsonl-file into a memory."""
with open(dataset_path, "r") as fd:
return [json.loads(json_line) for json_line in fd]
编码器定义¶
我们将使用来自 sentence-transformers 库的预训练模型 all-MiniLM-L6-v2 作为我们的文本编码器。
import os
from torch import Tensor, nn
from sentence_transformers.models import Transformer, Pooling
from quaterion_models.types import TensorInterchange, CollateFnType
from quaterion_models.encoders import Encoder
class FAQEncoder(Encoder):
def __init__(self, transformer, pooling):
super().__init__()
self.transformer = transformer
self.pooling = pooling
self.encoder = nn.Sequential(self.transformer, self.pooling)
@property
def trainable(self) -> bool:
# Defines if we want to train encoder itself, or head layer only
return False
@property
def embedding_size(self) -> int:
return self.transformer.get_word_embedding_dimension()
def forward(self, batch: TensorInterchange) -> Tensor:
return self.encoder(batch)["sentence_embedding"]
def get_collate_fn(self) -> CollateFnType:
# `collate_fn` is a function that converts input samples into Tensor(s) for use as encoder input.
return self.transformer.tokenize
@staticmethod
def _transformer_path(path: str) -> str:
# just an additional method to reduce amount of repeated code
return os.path.join(path, "transformer")
@staticmethod
def _pooling_path(path: str) -> str:
return os.path.join(path, "pooling")
def save(self, output_path: str):
# to provide correct saving of encoder layers we need to implement it manually
transformer_path = self._transformer_path(output_path)
os.makedirs(transformer_path, exist_ok=True)
pooling_path = self._pooling_path(output_path)
os.makedirs(pooling_path, exist_ok=True)
self.transformer.save(transformer_path)
self.pooling.save(pooling_path)
@classmethod
def load(cls, input_path: str) -> Encoder:
transformer = Transformer.load(cls._transformer_path(input_path))
pooling = Pooling.load(cls._pooling_path(input_path))
return cls(transformer=transformer, pooling=pooling)
我们在 trainable 中返回 False - 这意味着我们的编码器是冻结的,其权重在训练期间不会改变。
可训练模型构建¶
Quaterion 中的主要实体之一是 TrainableModel。它处理大部分训练流程,并从模块构建最终模型。在这里,我们需要配置编码器、头部层、损失函数、优化器、指标、缓存等。TrainableModel 实际上是 pytorch_lightning.LightningModule,因此继承了所有 LightningModule 的特性。
from quaterion.eval.attached_metric import AttachedMetric
from torch.optim import Adam
from quaterion import TrainableModel
from quaterion.train.cache import CacheConfig, CacheType
from quaterion.loss import MultipleNegativesRankingLoss
from sentence_transformers import SentenceTransformer
from quaterion.eval.pair import RetrievalPrecision, RetrievalReciprocalRank
from sentence_transformers.models import Transformer, Pooling
from quaterion_models.heads.skip_connection_head import SkipConnectionHead
class FAQModel(TrainableModel):
def __init__(self, lr=10e-5, *args, **kwargs):
self.lr = lr
super().__init__(*args, **kwargs)
def configure_metrics(self):
# attach batch-wise metrics which will be automatically computed and logged during training
return [
AttachedMetric(
"RetrievalPrecision",
RetrievalPrecision(k=1),
prog_bar=True,
on_epoch=True,
),
AttachedMetric(
"RetrievalReciprocalRank",
RetrievalReciprocalRank(),
prog_bar=True,
on_epoch=True
),
]
def configure_optimizers(self):
return Adam(self.model.parameters(), lr=self.lr)
def configure_loss(self):
# `symmetric` means that we take into account correctness of both the closest answer to a question and the closest question to an answer
return MultipleNegativesRankingLoss(symmetric=True)
def configure_encoders(self):
pre_trained_model = SentenceTransformer("all-MiniLM-L6-v2")
transformer: Transformer = pre_trained_model[0]
pooling: Pooling = pre_trained_model[1]
encoder = FAQEncoder(transformer, pooling)
return encoder
def configure_head(self, input_embedding_size: int):
return SkipConnectionHead(input_embedding_size)
def configure_caches(self):
# Cache stores frozen encoder embeddings to prevent repeated calculations and increase training speed.
# AUTO preserves the current encoder's device as storage, batch size does not affect training and is used only to fill the cache before training.
return CacheConfig(CacheType.AUTO, batch_size=256)
训练与评估¶
我们将合并最后两个步骤,并在一个函数中执行训练和评估。对于训练过程,我们需要创建 pytorch_lightning.Trainer 实例来处理训练流程,还需要数据集和数据加载器实例来准备数据并将其馈送到模型。最后,要启动训练过程,所有这些都应该传递给 Quaterion.fit。批次评估将在训练期间进行,但它可能会根据批次大小波动很大。通过 Evaluator 和 Quaterion.evaluate 可以获得更具代表性的、来自更大部分数据的结果。
最后,训练好的模型会保存在 servable 目录下。
import os
import torch
import pytorch_lightning as pl
from quaterion import Quaterion
from quaterion.dataset import PairsSimilarityDataLoader
from quaterion.eval.evaluator import Evaluator
from quaterion.eval.pair import RetrievalReciprocalRank, RetrievalPrecision
from quaterion.eval.samplers.pair_sampler import PairSampler
DATA_DIR = 'data'
def run(model, train_dataset_path, val_dataset_path, params):
use_gpu = params.get("cuda", torch.cuda.is_available())
trainer = pl.Trainer(
min_epochs=params.get("min_epochs", 1),
max_epochs=params.get("max_epochs", 300), # cache makes it possible to use a huge amount of epochs
auto_select_gpus=use_gpu,
log_every_n_steps=params.get("log_every_n_steps", 10), # increase to speed up training
gpus=int(use_gpu),
num_sanity_val_steps=2,
)
train_dataset = FAQDataset(train_dataset_path)
val_dataset = FAQDataset(val_dataset_path)
train_dataloader = PairsSimilarityDataLoader(train_dataset, batch_size=1024)
val_dataloader = PairsSimilarityDataLoader(val_dataset, batch_size=1024)
Quaterion.fit(model, trainer, train_dataloader, val_dataloader)
metrics = {
"rrk": RetrievalReciprocalRank(),
"rp@1": RetrievalPrecision(k=1)
}
sampler = PairSampler()
evaluator = Evaluator(metrics, sampler)
results = Quaterion.evaluate(evaluator, val_dataset, model.model) # calculate metrics on the whole dataset to obtain more representative metrics values
print(f"results: {results}")
# launch training
pl.seed_everything(42, workers=True)
faq_model = FAQModel()
train_path = os.path.join(DATA_DIR, "train_cloud_faq_dataset.jsonl")
val_path = os.path.join(DATA_DIR, "val_cloud_faq_dataset.jsonl")
run(faq_model, train_path, val_path, {})
faq_model.save_servable("servable")
以下是训练期间观察到的一些图表。如您所见,损失下降,而指标稳步增长。
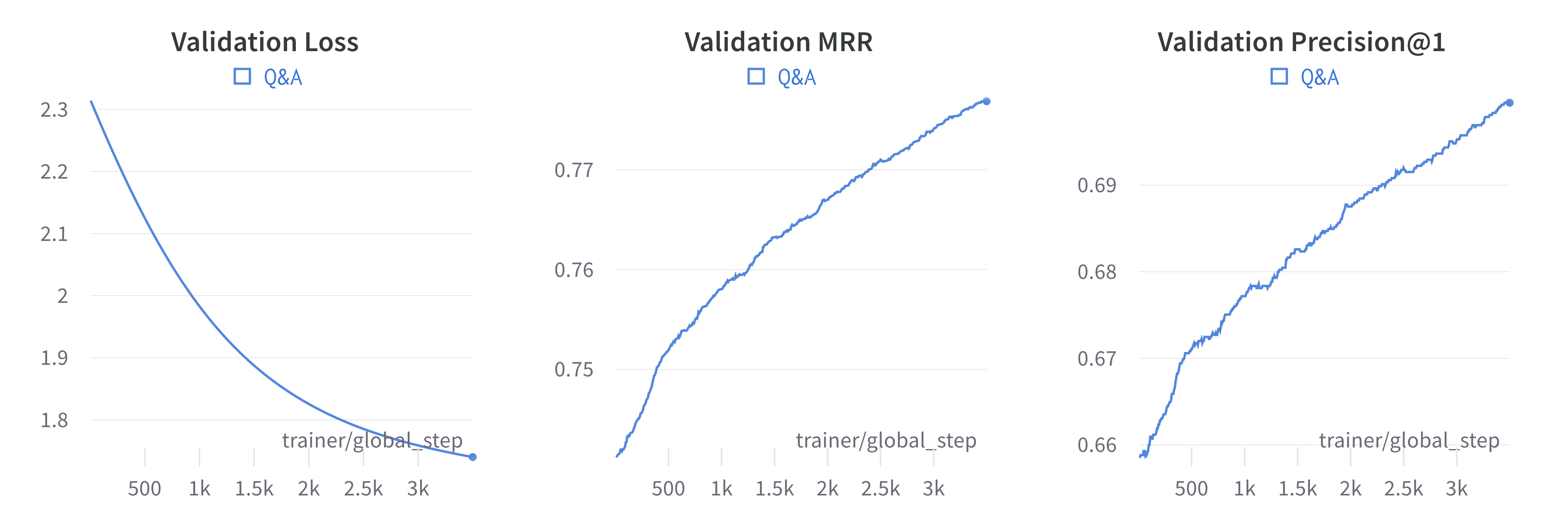
学习曲线¶
此外,我们来看一下模型的性能
Q: what is the pricing of aws lambda functions powered by aws graviton2 processors?
A: aws lambda functions powered by aws graviton2 processors are 20% cheaper compared to x86-based lambda functions
Q: can i run a cluster or job for a long time?
A: yes, you can run a cluster for as long as is required
Q: what is the dell open manage system administrator suite (omsa)?
A: omsa enables you to perform certain hardware configuration tasks and to monitor the hardware directly via the operating system
Q: what are the differences between the event streams standard and event streams enterprise plans?
A: to find out more information about the different event streams plans, see choosing your plan
就是这样!我们刚刚训练了一个相似度学习模型来解决问答问题!
进一步学习¶
如果您一步一步地跟着教程进行,可能会对 Quaterion 的训练速度感到惊讶。这主要归功于缓存和冻结的编码器。请查看我们的 缓存教程。
