Triplet Loss 是相似性学习中最广为人知的损失函数之一。如果您想深入了解其实现细节和优势,可以阅读这篇先前的教程。
尽管 Triplet Loss 很受欢迎且成功,但它也存在所谓的向量坍缩问题,这是相似性学习中的一个常见问题。向量空间的坍缩是指编码器通过简单地将所有输入样本映射到向量空间中的一个单点(或非常小的区域)来满足损失函数,而没有真正学习到对任务有用的特征。在这种情况下,当你查看损失曲线图时,你会看到损失值在少量步骤后下降,然后突然下降到一个非常接近边距值的稳定值。这在 batch-hard 策略中可能会观察到,该策略通常更受欢迎,因为它不那么贪婪,如果可以避免向量空间坍缩问题,其性能会优于 batch-all 策略。
坍缩模型的损失
修复后的损失 |
我们来看看为什么会发生这种情况。 |
|---|---|
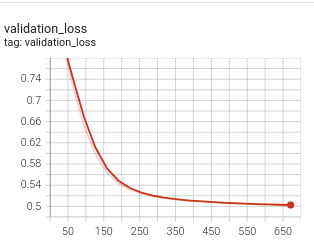
|
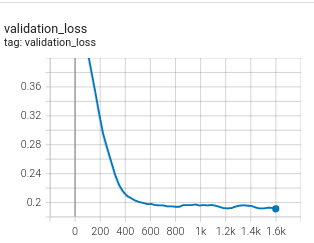
|
batch-hard 策略计算 Triplet Loss 的方式是,将最难的锚点-正样本对与最难的锚点-负样本对之间的距离的绝对差值与边距值相加。最难的锚点-正样本对是距离最大的样本对,而最难的锚点-负样本对是距离最小的样本对。
在其基本形式中,该值的计算方式如下
这个公式的问题在于,如果编码器对所有样本输出相同的向量,那么损失值将等于边距值,并且不会再有改进。
triplet_loss = F.relu(
hardest_positive_dists - hardest_negative_dists
+ self._margin
)
为了防止损失值停留在边距值,Quaterion 添加了一个小技巧,即用最难的锚点-负样本对距离的均值来缩放差值,代码变为
这种除法技巧在最难的锚点-负样本对之间距离较大时引入了额外的惩罚,模型可以继续改进以达到小于边距值的损失,这正是我们在实验中观察到的情况。
triplet_loss = F.relu(
(hardest_positive_dists - hardest_negative_dists)
/ hardest_negative_dists.mean()
+ self._margin
)
